This blog post is the culmination of a long series of blog posts on the statistics of color difference data. Most of them just basically said "yeah, normal stats don't work". Lotta help that is, eh? Several blog posts alluded to the fact that I did indeed have a solution. The most recent of which alluded to a method that works in the very title of the blog post: Statistical process control of color, approaching a method that works.

Now it's time to unveil the method.
Generalization of the standard deviation
One way of describing the technique is to call it a generalization of the standard deviation to multiple dimensions -- three dimensions if we are dealing with color data. That's a rather abstract concept, so I will explain.
One dimensional standard deviation
We can think of our good friends, the standard deviation and mean, as describing a line segment on the number line, as illustrated below. If the data is normally distributed (also called Gaussian, or bell curve), then you would expect that about 68% of the data will fall on the line segment within one standard deviation unit (one sigma) of the mean, 95.45% of the data will fall within two sigma of the mean, and 99.73% of the data will be within three sigma of the mean.

As an aside, note that not all data is normally distributed. This holds true for color difference data, which is the issue that got me started down this path!
So, a one-dimensional standard deviation can be thought of as a line segment that is 2 sigma long, and centered on the mean of the data. It is a one-dimensional summary of all the underlying data.
Two-dimensional standard deviation
Naturally, a two-dimensional standard deviation is a two-dimensional summary of the underlying two-dimensional data. But instead of a (one-dimensional) line segment, we get an ellipse in two dimensions.
In the simplest case, the two-dimensional standard deviation is a circle (shown in orange below) which is centered on the average of the data points. The circle has a radius of one sigma. If you want to get all mathematical about this, the circle represents a portion of a two-dimensional Gaussian distribution with 39% of the data falling inside the circle, and 61% falling outside.

I slipped a number into that last paragraph that deserves to be underlined: 39%. Back when we were dealing with one-dimensional data, +/- one sigma would encompass 68% of normally distributed data. The number for two-dimensional data is 39%. Toto, I have a feeling we're not in one-dimensional-normal-distribution-ville anymore.
Of course, not all two-dimensional standard deviations are circular like the one in the drawing above. More generally, they will be ellipses. The the length of the semi-major and semi-minor axes of the ellipse are the major and minor standard deviation.
--- Taking a break for a moment
I better stop to review some pesky vocabulary terms. A circle has a radius, which is the distance from the center of the circle to any point on the circle. A circle also has a diameter, which is the distance between opposite points on the circle. The diameter is twice the radius.
When we talk about ellipses, we generally refer to the two axes of the ellipse. The major axis is the longest line segment that goes through the center of the ellipse. The minor axis is the shortest line segment that goes through the center of the ellipse. The lengths of the major and minor axes are essentially the extremes of the diameters of the ellipse. They run perpendicular to each other.

There is no convenient word for the two "radii" of an ellipse. All we have is the inconvenient phrases semi-major axis and semi-major axis. These are half the length of the major and minor axes, respectively.
--- Break over, time to get back to work
The axes of the ellipses won't necessarily be straight up and down and left-to-right on a graph. So, the full description of the two-dimensional standard deviation must include information to identify the orientation of these axes.
The image below shows a set of hypothetical two-dimensional data that has been ellipsified. The red dots are random data that was generated using Mathematica. I asked it to give me 200 normally distributed x data points with a standard deviation of 3, and 200 normally distributed y data points with a standard deviation of 1. These original data points (the x and y values) were uncorrelated.
This collection of data points were then rotated by 15 degrees so that the new x values had a bit of y in them, and the new y values had a bit of x in them. In other words, there was some correlation (r = 0.6) between the new x and y. I then added 6 to the new x values and 3 to the new y values to move the center of the ellipse. So, the red data points are designed to represent some arbitrary data set that could just happen in real life.
I performed an ellipsification, and have plotted the one, two, and three sigma ellipses (in pink). The major and minor axes of the one sigma ellipse are shown in blue.

The result of ellipsifying this data is all the parameters pertaining to the innermost of the ellipses in the image above. This is an ellipse that is centered on {6.11, 3.08}, with major axis of 3.19 and minor axis of 1.00. The ellipse is oriented at 15.8 degrees. These are all rather close to the original parameters that I started with, so I musta done sumthin right.
I also counted the number of data points within the three ellipses. I counted 38.5% in the 1 sigma ellipse, 88.5% in the 2 sigma ellipse, and 99% in the 3 sigma ellipse. (Of course when I say I did this, I really mean that Mathematica gave me a little help.) If the data follows a two-dimensional normal distribution, then the ellipses will encompass 39%, 86.5%, and 98.9% of the data. This is one indication that this condition is met.
The following pieces of information are determined in the ellipsification process of two-dimensional data:
a) The average of the data which is the center of the ellipse (two numbers, for the horizontal and vertical values)
b) The orientation of the ellipse (which could be a single number, such as the rotation angle)
c) The lengths of the semi-major and semi-minor axes of the ellipse (two numbers)
The ellipsification can be described in other ways, but these five numbers will tell me everything about the ellipse. The ellipse is the statistical proxy for the whole data set.
Three-dimensional standard deviation
The extension to three-dimensional standard deviation is "obvious". (Obvious is a mathematician's way of saying "I don't have the patience to explain this to mere mortals.")
The result of ellipsifying three-dimensional data is the following nine pieces of information that are necessary to describe an arbitrary (three-dimensional) ellipsoid:
a) The average of the data (three numbers, for the average of the x, y, and z values)
b) The orientation of the ellipsoid (three numbers defining the direction that the axes point)
c) The lengths of the semi-major, semi-medial, and semi-minor axes of the ellipse (three numbers)
The image below is an ellipsification of real color data. The data is the color of a solid patch as produced by 102 different newspaper printing presses. There were two samples of this patch from each press, so the number of dots is 204.
The 204 dots were used to compute the three-dimensional standard deviation, which is represented by the three lines. The longest line, the red line, is the major axis of the ellipse, and has a length of 5.6 CIELAB units. The green and blue lines are the medial and minor axes, respectively. They 2.2 and 2.1 CIELAB units long. All three of the axes meet at the mean of all the data points, and all three are two-sigma long (+/-1 sigma from the mean). Depending on the angle you are looking, it may not appear that the axes are all perpendicular to each other, but they are.

Trouble viewing the image above? The image is a .gif image, so you should see it rotating. If it doesn't, then try a different browser, or download it to your computer and view it directly.
What can we do with the ellipsification?
The ellipsification of color data is a three-dimensional version of the standard deviation, so in theory, we can use it for anything that we would use the standard deviation for. The most common use (in the realm of statistical process control) is to decide whether a given data point is an example of typical process variation, or if there is some nefarious agent at work. (Deming would call that a special cause.)
We will see an example of this on real data in the next blog post on the topic: Statistics of multi-dimensional data, example.

Now it's time to unveil the method.
Generalization of the standard deviation
One way of describing the technique is to call it a generalization of the standard deviation to multiple dimensions -- three dimensions if we are dealing with color data. That's a rather abstract concept, so I will explain.
One dimensional standard deviation
We can think of our good friends, the standard deviation and mean, as describing a line segment on the number line, as illustrated below. If the data is normally distributed (also called Gaussian, or bell curve), then you would expect that about 68% of the data will fall on the line segment within one standard deviation unit (one sigma) of the mean, 95.45% of the data will fall within two sigma of the mean, and 99.73% of the data will be within three sigma of the mean.

As an aside, note that not all data is normally distributed. This holds true for color difference data, which is the issue that got me started down this path!
So, a one-dimensional standard deviation can be thought of as a line segment that is 2 sigma long, and centered on the mean of the data. It is a one-dimensional summary of all the underlying data.
Two-dimensional standard deviation
Naturally, a two-dimensional standard deviation is a two-dimensional summary of the underlying two-dimensional data. But instead of a (one-dimensional) line segment, we get an ellipse in two dimensions.
In the simplest case, the two-dimensional standard deviation is a circle (shown in orange below) which is centered on the average of the data points. The circle has a radius of one sigma. If you want to get all mathematical about this, the circle represents a portion of a two-dimensional Gaussian distribution with 39% of the data falling inside the circle, and 61% falling outside.

Two dimensional histogram of a simple set of two dimensional data
The orange line encompasses 39% of the volume.
The orange line encompasses 39% of the volume.
I slipped a number into that last paragraph that deserves to be underlined: 39%. Back when we were dealing with one-dimensional data, +/- one sigma would encompass 68% of normally distributed data. The number for two-dimensional data is 39%. Toto, I have a feeling we're not in one-dimensional-normal-distribution-ville anymore.
Of course, not all two-dimensional standard deviations are circular like the one in the drawing above. More generally, they will be ellipses. The the length of the semi-major and semi-minor axes of the ellipse are the major and minor standard deviation.
--- Taking a break for a moment
I better stop to review some pesky vocabulary terms. A circle has a radius, which is the distance from the center of the circle to any point on the circle. A circle also has a diameter, which is the distance between opposite points on the circle. The diameter is twice the radius.
When we talk about ellipses, we generally refer to the two axes of the ellipse. The major axis is the longest line segment that goes through the center of the ellipse. The minor axis is the shortest line segment that goes through the center of the ellipse. The lengths of the major and minor axes are essentially the extremes of the diameters of the ellipse. They run perpendicular to each other.
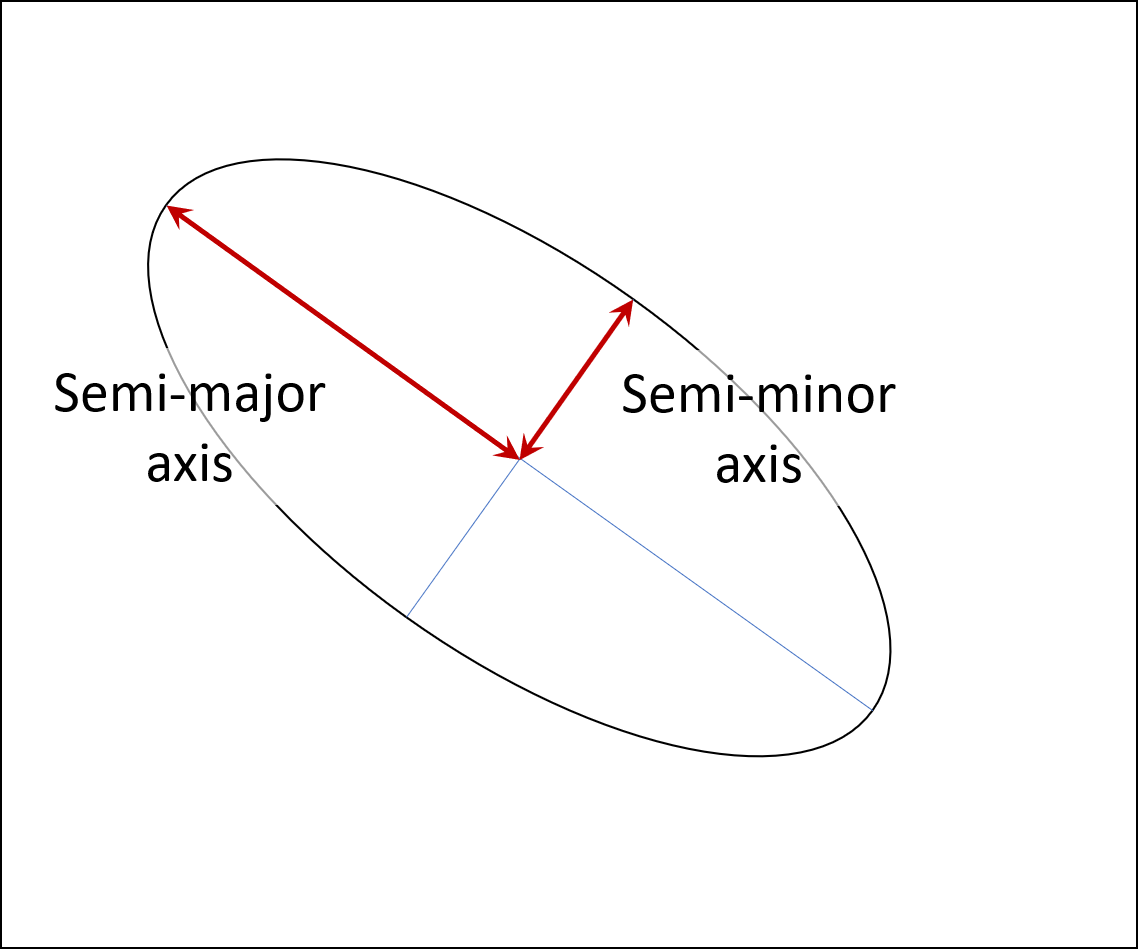
An ellipse, showing off the most gorgeous set of axes I've ever seen
There is no convenient word for the two "radii" of an ellipse. All we have is the inconvenient phrases semi-major axis and semi-major axis. These are half the length of the major and minor axes, respectively.
The axes of the ellipses won't necessarily be straight up and down and left-to-right on a graph. So, the full description of the two-dimensional standard deviation must include information to identify the orientation of these axes.
The image below shows a set of hypothetical two-dimensional data that has been ellipsified. The red dots are random data that was generated using Mathematica. I asked it to give me 200 normally distributed x data points with a standard deviation of 3, and 200 normally distributed y data points with a standard deviation of 1. These original data points (the x and y values) were uncorrelated.
This collection of data points were then rotated by 15 degrees so that the new x values had a bit of y in them, and the new y values had a bit of x in them. In other words, there was some correlation (r = 0.6) between the new x and y. I then added 6 to the new x values and 3 to the new y values to move the center of the ellipse. So, the red data points are designed to represent some arbitrary data set that could just happen in real life.
I performed an ellipsification, and have plotted the one, two, and three sigma ellipses (in pink). The major and minor axes of the one sigma ellipse are shown in blue.

Gosh darn! that's purdy!
The result of ellipsifying this data is all the parameters pertaining to the innermost of the ellipses in the image above. This is an ellipse that is centered on {6.11, 3.08}, with major axis of 3.19 and minor axis of 1.00. The ellipse is oriented at 15.8 degrees. These are all rather close to the original parameters that I started with, so I musta done sumthin right.
I also counted the number of data points within the three ellipses. I counted 38.5% in the 1 sigma ellipse, 88.5% in the 2 sigma ellipse, and 99% in the 3 sigma ellipse. (Of course when I say I did this, I really mean that Mathematica gave me a little help.) If the data follows a two-dimensional normal distribution, then the ellipses will encompass 39%, 86.5%, and 98.9% of the data. This is one indication that this condition is met.
The following pieces of information are determined in the ellipsification process of two-dimensional data:
a) The average of the data which is the center of the ellipse (two numbers, for the horizontal and vertical values)
b) The orientation of the ellipse (which could be a single number, such as the rotation angle)
c) The lengths of the semi-major and semi-minor axes of the ellipse (two numbers)
The ellipsification can be described in other ways, but these five numbers will tell me everything about the ellipse. The ellipse is the statistical proxy for the whole data set.
Three-dimensional standard deviation
The extension to three-dimensional standard deviation is "obvious". (Obvious is a mathematician's way of saying "I don't have the patience to explain this to mere mortals.")
The result of ellipsifying three-dimensional data is the following nine pieces of information that are necessary to describe an arbitrary (three-dimensional) ellipsoid:
a) The average of the data (three numbers, for the average of the x, y, and z values)
b) The orientation of the ellipsoid (three numbers defining the direction that the axes point)
c) The lengths of the semi-major, semi-medial, and semi-minor axes of the ellipse (three numbers)
The image below is an ellipsification of real color data. The data is the color of a solid patch as produced by 102 different newspaper printing presses. There were two samples of this patch from each press, so the number of dots is 204.
The 204 dots were used to compute the three-dimensional standard deviation, which is represented by the three lines. The longest line, the red line, is the major axis of the ellipse, and has a length of 5.6 CIELAB units. The green and blue lines are the medial and minor axes, respectively. They 2.2 and 2.1 CIELAB units long. All three of the axes meet at the mean of all the data points, and all three are two-sigma long (+/-1 sigma from the mean). Depending on the angle you are looking, it may not appear that the axes are all perpendicular to each other, but they are.

Ellipsification of some real data, as shown with the axes of the ellipsoid
Trouble viewing the image above? The image is a .gif image, so you should see it rotating. If it doesn't, then try a different browser, or download it to your computer and view it directly.
What can we do with the ellipsification?
The ellipsification of color data is a three-dimensional version of the standard deviation, so in theory, we can use it for anything that we would use the standard deviation for. The most common use (in the realm of statistical process control) is to decide whether a given data point is an example of typical process variation, or if there is some nefarious agent at work. (Deming would call that a special cause.)
We will see an example of this on real data in the next blog post on the topic: Statistics of multi-dimensional data, example.
To characterize an ellipsoid, only 8 numbers are needed. Orientation requires just 2 numbers (e.g. two angles, or a vector with module one). Or just the coordinates of center and of one pole (3+3), but then one semi-axis can be calculated, so we need just the two additional distances.
ReplyDeleteThanks for the comment, cate. I have gone back and forth on this question several times. Right now, I think I disagree with you. :)
DeleteLet's say we start with a unit sphere, with centroid at the origin. How do I transform this into an arbitrary ellipsoid?
First, we can scale the x, the y, and the z axes to account for the length of the three axes of the ellipsoid. Three parameters used up. (Note: I was confused by this for a while. I got hung up thinking -- erroneously -- that ellipsoids were either prolate or oblate. I still have trouble picturing an ellipsoid that is neither.)
Second, we orient the major axis. We can do this with two angles, as you have said. I like to think of the two angles as latitude and longitude. Two more parameters, bringing this up to five.
Third, the medial and minor axes lie in a plane which is perpendicular to the direction that the major axis points, but we need to account for rotation of the ellipsoid around that major axis. This defines the direction that the medial axis points within the plane. This is one more parameter, bringing us up to six. (Note: Another spot of confusion for me. initially, I missed this one.)
Fourth, we need an offset in x, in y, and in z to center the ellipsoid arbitrarily. Three more parameters, bringing us up to nine.
Is there a flaw in what I am thinking?